

Jensen Huang walked onto a darkened stage in San Jose on Monday evening and, over the course of roughly two hours, laid out a vision for the next era of computing that even by his own standards felt audacious. The NVIDIA CEO told a packed audience at the SAP Center that combined purchase orders for the company's Blackwell and upcoming Vera Rubin chip platforms will reach $1 trillion through 2027. That figure, double the $500 billion projection he floated at last year's GTC, reflects the pace at which hyperscalers, sovereign governments, and enterprise customers are racing to build out AI infrastructure. But the trillion-dollar number was just the opening act. What followed was a cascade of product launches, automotive partnerships, and software announcements that collectively argue NVIDIA is no longer simply selling chips. It is building the operating system for the age of AI.
GTC 2026 also marked the 20th anniversary of CUDA, the parallel computing platform that gave NVIDIA its stranglehold on accelerated computing. Huang leaned on that history to frame the current moment: Moore's Law, he argued, has stalled, and the only path forward for performance gains runs through NVIDIA's vertically integrated stack. That stack now spans data center GPUs, inference-specific processors, autonomous driving platforms, robotics frameworks, space computing modules, and an open-source agentic AI runtime. The sheer breadth of announcements was designed to make a single point. Every layer of computing, from silicon to software, needs to be rethought for a world where AI agents, not humans, consume the majority of compute cycles.
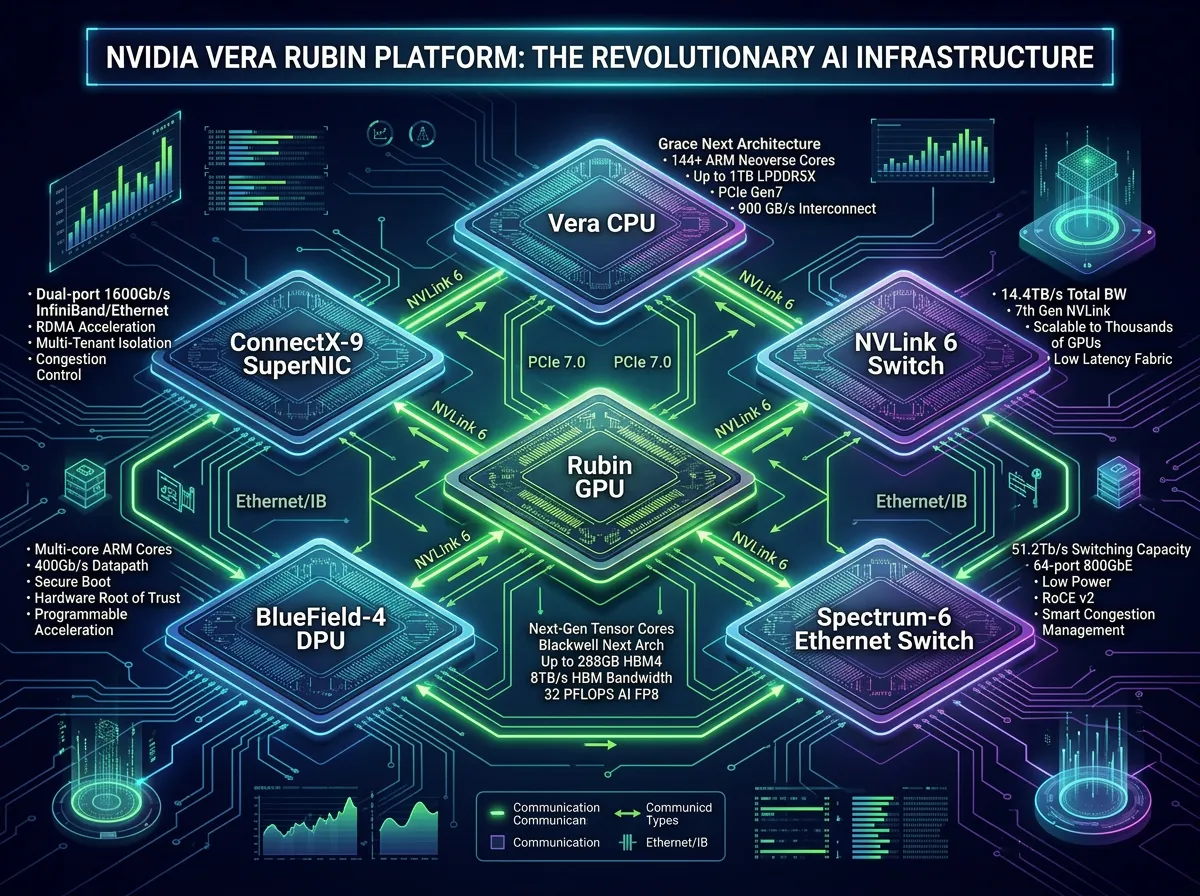
Six Chips, One Supercomputer: The Vera Rubin Platform
The centerpiece hardware announcement was the full Vera Rubin platform, a rack-scale system built from six co-designed chips: the Rubin GPU, Vera CPU, NVLink 6 Switch, ConnectX-9 SuperNIC, BlueField-4 DPU, and Spectrum-6 Ethernet Switch. Each Rubin GPU delivers 50 petaflops in FP4 inference, up from 20 petaflops on Blackwell, and the full NVL72 rack configuration (72 GPUs, 36 CPUs) pushes aggregate performance to 3.6 exaflops. NVIDIA claims the system delivers 10 times more performance per watt than the Grace Blackwell generation, and one-tenth the cost per token for inference workloads.
The Vera CPU itself is a significant departure from NVIDIA's previous reliance on Arm-based Grace processors. Built around 88 custom Olympus cores with Armv9.2 compatibility, each core supports what NVIDIA calls Spatial Multithreading, allowing two simultaneous execution threads. The chip uses LPDDR5X memory and delivers up to 1.2 TB/s of memory bandwidth at half the power draw of comparable general-purpose server CPUs. A dedicated Vera CPU rack holds 256 liquid-cooled processors, supports 22,500 concurrent CPU environments, and packs 400 TB of total memory. Partners will begin shipping Vera Rubin systems in the second half of 2026, with the Vera Rubin Ultra variant (doubling Rubin's performance to 100 petaflops per GPU) slated for 2027.
Anthropic CEO Dario Amodei said the platform "gives us the compute, networking, and system design" required for complex agentic workflows. OpenAI CEO Sam Altman noted it enables his company to "run more powerful models and agents at massive scale." Both endorsements hint at how tightly the frontier model labs are now coupled to NVIDIA's hardware roadmap. When your two largest customers for AI training silicon publicly vouch for your next-generation platform at your own conference, the competitive moat looks deep.
Groq 3: NVIDIA's First Inference-Only Chip
Perhaps the most intriguing silicon announcement was the Groq 3 Language Processing Unit, the first product to emerge from NVIDIA's $20 billion acquisition of Groq in December 2025. The deal, NVIDIA's largest ever, brought Groq founder Jonathan Ross and president Sunny Madra into the NVIDIA fold along with a team that had spent years building processors specifically for AI inference rather than training. The Groq 3 LPU is packed with 500 MB of SRAM per chip, providing 150 TB/s of on-chip bandwidth. For context, the HBM4 memory on each Rubin GPU offers 22 TB/s. The SRAM-heavy design lets the Groq 3 accelerate "every layer of the AI model on every token," according to NVIDIA, making it purpose-built for the latency-sensitive inference workloads that dominate agentic AI.
The Groq 3 LPX rack holds 256 LPUs and is designed to sit alongside the Vera Rubin NVL72 in a complementary configuration. When paired together, NVIDIA claims customers will see 35 times higher throughput per megawatt of power and 10 times more revenue opportunity compared to running Rubin alone. The LPX rack ships in Q3 2026. This is a notable strategic shift for a company that historically sold one GPU architecture for both training and inference. By acquiring Groq and integrating its LPU into the platform, NVIDIA is acknowledging that the inference market, where models serve millions of concurrent users, requires fundamentally different hardware than the training market. The move also preemptively neutralizes one of the strongest arguments competing chip startups had been making: that general-purpose GPUs are wasteful for pure inference workloads.
For NVIDIA investors who watched the company post $68 billion in quarterly revenue just weeks ago, the Groq 3 launch signals where the next leg of growth will come from. As AI shifts from a training-dominated phase to an inference-dominated one, having purpose-built silicon for both workloads positions NVIDIA to capture spending on either side of the transition.
The Autonomous Vehicle Land Grab
NVIDIA used GTC 2026 to make its most aggressive push yet into autonomous driving. Huang announced that BYD, Geely, Isuzu, and Nissan are all developing Level 4 autonomous vehicles on the NVIDIA DRIVE Hyperion platform, joining Hyundai and Kia, which expanded their existing partnership to include both Level 2 driver assistance integration and Level 4 robotaxi development through the Motional joint venture. "Everything that moves will eventually be autonomous," Huang told the audience. "The NVIDIA Hyperion platform and our Alpamayo open reasoning models give vehicles the ability to perceive their surroundings, reason through complex situations and act safely."
The Uber partnership may prove to be the most commercially significant of the bunch. NVIDIA and Uber announced a plan to deploy autonomous ride-hail vehicles powered by the full NVIDIA DRIVE AV software stack across 28 cities on four continents by 2028. The rollout begins in Los Angeles and the San Francisco Bay Area in the first half of 2027, then expands to major hubs in North America, Europe, Australia, and Asia. Each city will follow a phased deployment: data-collection vehicles first, then operator-supervised rides, and finally fully driverless Level 4 service. Uber CEO Dara Khosrowshahi said "autonomous technology holds enormous promise to make transportation safer, more reliable, and more accessible."

The technical backbone of these deployments is the Alpamayo 1.5 open model, which has been downloaded by more than 100,000 automotive developers since its initial release. Alpamayo supports interactive reasoning with multi-camera inputs and configurable parameters, letting developers adapt the model to city-specific driving conditions. The NVIDIA Halos operating system provides the safety layer, offering ASIL D-certified architecture with three tiers of redundancy for production-ready autonomy. Meanwhile, Omniverse NuRec, using 3D Gaussian Splatting, generates high-fidelity simulation environments for testing and validation without putting physical vehicles on the road.
The automotive push also includes Isuzu and TIER IV's collaboration on autonomous buses using the DRIVE AGX Thor system-on-a-chip, and partnerships with Bolt, Grab, and Lyft for robotaxi services in their respective markets. What NVIDIA is building here is not a single autonomous vehicle. It is an ecosystem where the hardware, software, safety certification, simulation tools, and ride-hail integration all flow through its platform.
DLSS 5: The "GPT Moment" for Graphics
On the gaming side, Huang announced DLSS 5, which he described as "the GPT moment for graphics." The technology combines traditional 3D rendering data (color buffers, motion vectors, depth maps) with a generative AI model trained to understand complex scene semantics, including characters, hair, fabric, and environmental lighting. The result is real-time neural rendering at up to 4K resolution, where the AI model fills in photoreal lighting and material detail that would otherwise require orders of magnitude more traditional compute to render.
NVIDIA's press release calls DLSS 5 "the most significant breakthrough in computer graphics since the debut of real-time ray tracing in 2018." That is a company making a claim about its own product, but the early reactions lend it some credibility. Digital Foundry founder Richard Leadbetter said he hadn't "seen a demo quite as astonishing as DLSS 5 for quite some time." Developers will receive granular controls for tuning intensity, color grading, and masking, letting art directors decide where the AI enhancements apply and where the original rendering takes precedence. DLSS 5 arrives in fall 2026 on RTX 50-series GPUs, with confirmed support from Bethesda (Starfield, The Elder Scrolls IV: Oblivion Remastered), CAPCOM (Resident Evil Requiem), Ubisoft (Assassin's Creed Shadows), and more than a dozen other studios and publishers.
Todd Howard, Bethesda's head of game development, called DLSS 5 "the next major step in pushing gaming graphics forward." CAPCOM's Jun Takeuchi described it as "another important step in pushing visual fidelity forward" for the Resident Evil franchise. The technology has obvious implications beyond gaming. Any real-time 3D application, from architectural visualization to surgical simulation, could benefit from AI-assisted rendering that dramatically reduces the compute required to produce photorealistic imagery.
NemoClaw and the Agentic AI Stack
The software side of GTC 2026 was dominated by the NemoClaw open-source stack, NVIDIA's answer to the question of how companies should deploy always-on AI agents safely. NemoClaw installs the NVIDIA OpenShell runtime (part of the NVIDIA Agent Toolkit) in a single command, providing a secure environment for autonomous agents along with open-source Nemotron models. The stack includes policy enforcement, network guardrails, and a privacy router that lets agents use local Nemotron models for sensitive tasks while routing to frontier cloud models when needed. Huang was characteristically blunt about the opportunity: "Every single company in the world today has to have an OpenClaw strategy."
The Anthropic-Pentagon standoff over AI safety constraints has made the governance layer of agentic AI a front-page issue. NemoClaw's privacy routing and policy enforcement are a direct response to that tension, offering enterprises a way to deploy powerful autonomous agents while maintaining control over what data leaves local infrastructure. Paired with the DGX Spark and DGX Station desktop systems (the latter featuring the GB300 Grace Blackwell Ultra Desktop Superchip with 748 GB of coherent memory and up to 20 petaflops of performance), NemoClaw gives developers a local-first platform for building, testing, and running AI agents without depending on cloud APIs.
NVIDIA also announced the Nemotron Coalition, a partner ecosystem organized around six frontier model families: Nemotron for language and reasoning, Cosmos for world and vision models, Isaac GR00T for general-purpose robotics, Alpamayo for autonomous driving, BioNeMo for biology and chemistry, and Earth-2 for weather and climate modeling. Each family comes with pre-trained models, fine-tuning tools, and deployment infrastructure. The breadth of the coalition underscores NVIDIA's strategy of owning not just the hardware layer but the model layer as well, giving it leverage at every point in the AI value chain.

From Earth to Orbit: Space-1 and the Feynman Roadmap
In a move that straddled the line between engineering ambition and showmanship, Huang previewed the Vera Rubin Space-1 module, a radiation-hardened chip system designed for orbital data centers. Built around two Rubin GPUs and a single Vera CPU, Space-1 delivers up to 25 times the AI performance of the H100 in a package engineered for the size, weight, and power constraints of spaceflight. Partners include Axiom Space, Planet Labs, and Starcloud. "Space computing, the final frontier, has arrived," Huang said, a line that prompted the kind of cheering usually reserved for product launches with immediate commercial impact. The practical applications are real, though: running large language models and foundation models directly in orbit eliminates the latency of downlinking raw data to Earth for processing.
Huang also extended the chip roadmap beyond Vera Rubin, confirming the Feynman architecture for 2028. Feynman GPUs will use TSMC's 1.6nm process and feature 3D die stacking, a first for NVIDIA. The architecture will pair a new LP40 LPU (co-developed with the Groq team) with the Rosa CPU, named after Rosalind Franklin. Feynman's Kyber networking system will replace the current Opera design, scaling from the NVL72 rack configuration in the Rubin generation to NVL1152 in the Feynman generation. Custom HBM, potentially an enhanced HBM4E or bespoke HBM5, will replace the standard high-bandwidth memory used in current architectures. The level of detail NVIDIA shared about a chip two years from production is unusual and deliberate. It tells hyperscalers exactly what to plan their data center buildouts around, and it tells competitors exactly how far ahead the roadmap extends.
The Trillion-Dollar Bet on Inference Economics
The $1 trillion purchase order figure deserves scrutiny. NVIDIA did not break down what portion of that total consists of confirmed contracts versus estimated demand pipeline, and the company has not disclosed the contractual terms underpinning the number. But even discounting it significantly, the trajectory it implies is staggering. NVIDIA posted $215.9 billion in total revenue for fiscal year 2026 and guided to approximately $78 billion for Q1 fiscal 2027 alone. A trillion dollars in orders through 2027, split across Blackwell systems already shipping and Vera Rubin systems arriving later this year, would require sustained quarterly revenue in the $80-100 billion range. That is aggressive, but it is not disconnected from the current growth curve.
What makes the projection plausible is the structural shift from training to inference. Training a frontier model is a one-time (or periodic) capital expenditure. Running that model for millions of users, 24 hours a day, across dozens of applications, is a recurring operational expense that scales with adoption. As agentic AI systems proliferate, doing everything from processing insurance claims to driving Uber vehicles, the inference compute required grows multiplicatively. NVIDIA's simultaneous launch of the Rubin GPU for training and the Groq 3 LPU for inference positions it to capture spending on both sides of that divide.
The cloud partnerships announced at GTC reinforce the scale of demand. AWS will deploy more than one million NVIDIA GPUs, including Blackwell, Rubin, and Groq 3 LPUs, beginning this year. Microsoft Azure has already deployed hundreds of thousands of liquid-cooled Grace Blackwell GPUs and became the first hyperscale cloud provider to power Vera Rubin NVL72 systems. NVIDIA Cloud Partners collectively doubled their AI factory footprint year-over-year, reaching more than one million deployed GPUs and 1.7 gigawatts of capacity. For companies like Apple, which just launched the iPhone 17e with its own custom C1x modem, the question of where on-device AI ends and cloud AI begins is increasingly shaped by the economics of NVIDIA's inference stack.
The picture that emerged from San Jose this week is a company that has moved past selling picks and shovels for the AI gold rush. NVIDIA is building the mines, the railroads, the power plants, and now the operating system. Whether any single entity should control that much of the AI supply chain is a question regulators will eventually have to answer. For now, the market has rendered its verdict: NVIDIA's stock rose in pre-market trading Tuesday, adding roughly $50 billion in market capitalization before the conference's second day had even begun.
Sources
- NVIDIA GTC 2026: Live Updates on What's Next in AI - NVIDIA Blog, March 16, 2026
- Nvidia GTC 2026: CEO Jensen Huang sees $1 trillion in orders for Blackwell and Vera Rubin through '27 - CNBC, March 16, 2026
- BYD, Geely, Isuzu and Nissan Adopt NVIDIA DRIVE Hyperion for Level 4 Vehicles - NVIDIA Newsroom, March 16, 2026
- NVIDIA DLSS 5 Delivers AI-Powered Breakthrough in Visual Fidelity for Games - NVIDIA Newsroom, March 16, 2026
- NVIDIA partners with BYD, Geely, Hyundai, Isuzu, Nissan and Uber - Electrive, March 17, 2026