
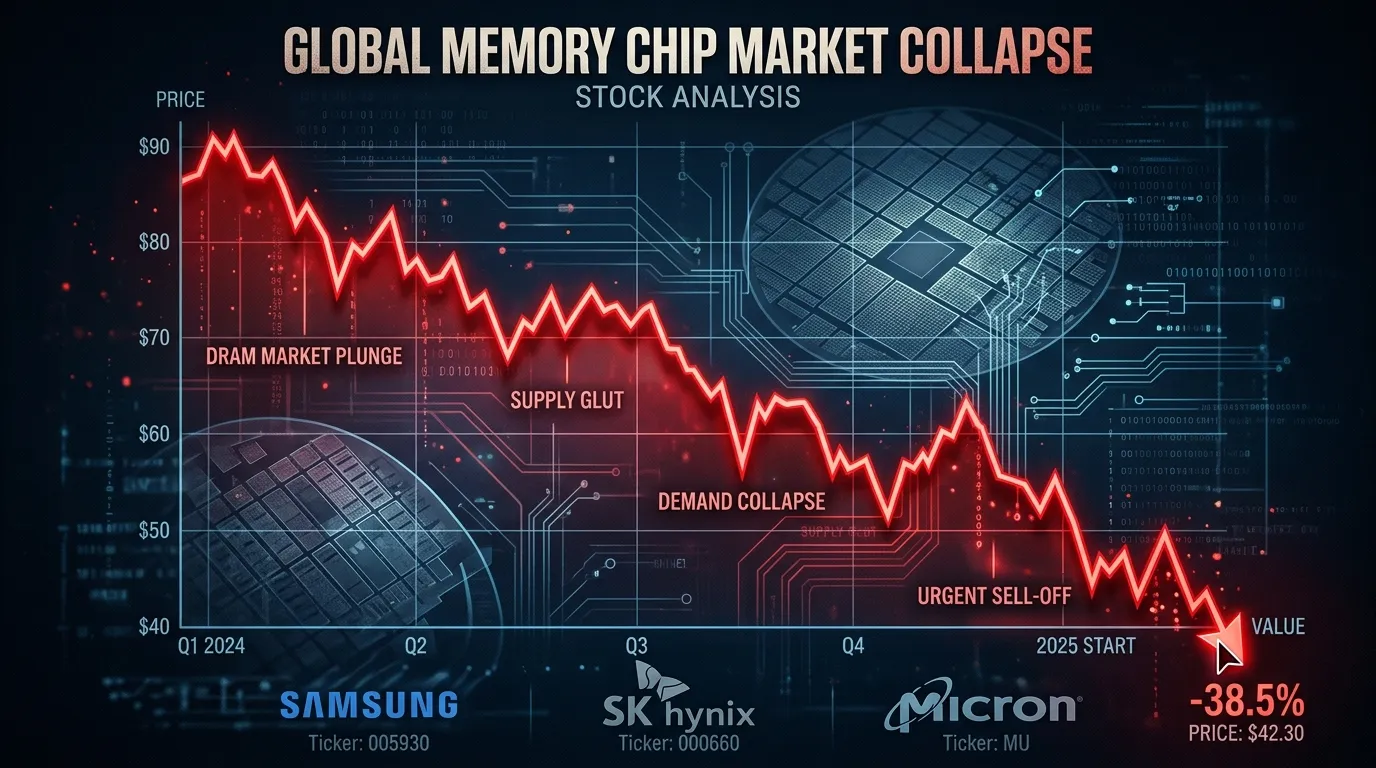
On March 24, two Google researchers published a blog post about a compression algorithm. By March 26, that blog post had erased more than $30 billion from the combined market capitalization of the world's largest memory chip manufacturers. SK Hynix fell 6.2%. Samsung tumbled 4.7%. Micron dropped over 5% across two sessions, extending a five-day slide to more than 20%. The algorithm is called TurboQuant, and the internet immediately compared it to Pied Piper, the fictional compression breakthrough from HBO's "Silicon Valley." The real-world version may be less dramatic than the stock market reaction suggests, but the questions it raises about the AI economy are worth understanding.
TurboQuant compresses a specific part of how large language models manage memory during conversations, cutting the data footprint by roughly 6x and speeding up a specific computation step by up to 8x on Nvidia H100 GPUs. Google says it does this with zero accuracy loss and requires no retraining. Within hours of the blog post, independent developers had built working implementations that confirmed the claims. The implications, if the technique scales to production systems, are straightforward: running AI gets significantly cheaper, and the memory chips that power it become less scarce.
That "if" is doing a lot of work.
What TurboQuant Actually Does
Every time you interact with an AI chatbot, the model maintains a running record of the conversation called the key-value (KV) cache. Think of it as the model's working memory. The cache grows with every exchange, consuming GPU memory that could otherwise be used for processing. For short prompts, this is manageable. For long documents, multi-step code reviews, or extended conversations, the cache can balloon beyond the model weights themselves, becoming the primary bottleneck.
"The moment you move beyond toy prompts and start working with long documents, multi-step workflows, or anything that needs context to persist, memory becomes the constraint," said Sanchit Vir Gogia, founder of Greyhound Research.
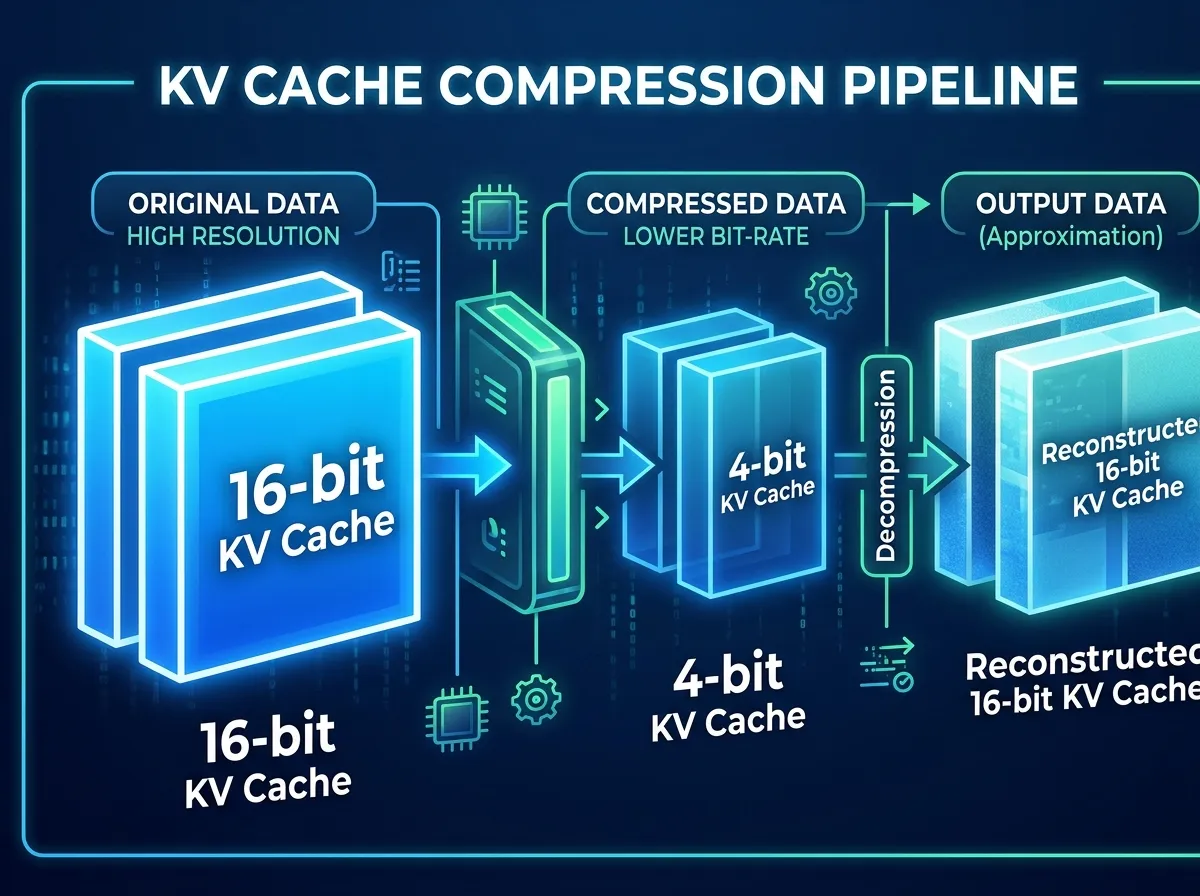
TurboQuant attacks this problem in two stages. The first, called PolarQuant, converts the data into polar coordinates, which makes the values easier to compress because their distributions become more predictable. The second stage, QJL, applies a single bit of error correction to clean up the residual noise. The combined result: 16-bit data compressed to 3 bits per value with, according to Google's benchmarks, character-identical outputs to uncompressed baselines.
The researchers, Amir Zandieh and Vahab Mirrokni of Google Research, tested TurboQuant across several open-source models including Llama 3.1, Gemma, and Mistral. The paper will be formally presented at ICLR 2026 in late April, with an open-source code release expected in Q2.
Why the Market Panicked
Investors drew a straight line from "AI needs less memory" to "memory chip makers sell fewer chips" and hit the sell button. The stocks that fell the hardest, Samsung, SK Hynix, Micron, Kioxia, SanDisk, and Western Digital, are the same companies whose shares had climbed 200-300% over the prior year on the back of insatiable AI demand. When a Google blog post suggested that demand might soften, the air came out fast.
The reaction echoed the DeepSeek R1 shock from January 2025, when an efficiency breakthrough from a Chinese AI lab briefly wiped $600 billion from Nvidia's market cap. Nvidia subsequently recovered and is now up 60% from that low, as the efficiency gains led to more AI adoption, not less.
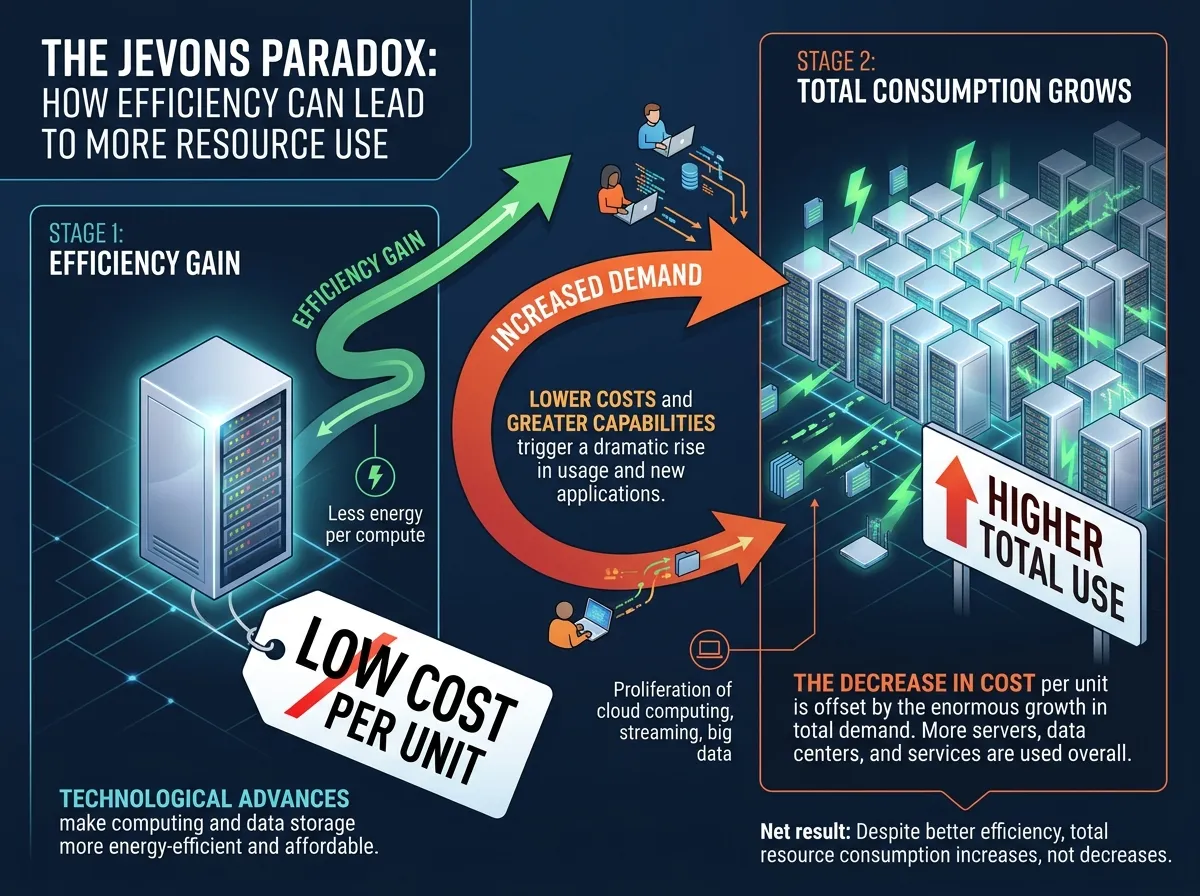
Shawn Kim, Head of Asia Technology Research at Morgan Stanley, explicitly invoked the parallel. He called the stock reaction "excessive" and characterized TurboQuant as Google's "DeepSeek moment." His core argument rests on Jevons Paradox, the 19th-century economic principle that efficiency gains in resource use tend to increase total consumption rather than decrease it. "If TurboQuant cuts AI operating costs to one-sixth of current levels, companies that have hesitated to adopt AI due to cost burdens will enter the AI ecosystem," Kim wrote. "This will not reduce total memory demand but rather serve as a catalyst that expands the overall AI market pie."

Vivek Arya at BofA Securities maintained his $500 price target on Micron, noting that similar compression techniques have circulated since 2024 without altering procurement patterns. He pointed to a revealing contradiction: despite publishing TurboQuant, Google raised its 2026 capital expenditure outlook to approximately $180 billion, up 100% year-over-year. If Google believed its own compression would meaningfully reduce infrastructure needs, that number would be going down, not up.
What the Skeptics Are Right About
The headline numbers, 6x compression and 8x speedup, deserve context. The 6x figure compares TurboQuant's 3-bit output to uncompressed 32-bit data. In practice, 70-80% of AI inference already runs on 8-bit precision, and edge applications use 4-bit. Against the baseline most companies actually operate at, the real-world memory reduction is closer to 2.6x. Still significant, but not the revolution the headlines suggest.
The 8x speedup applies specifically to attention-logit computation, one step in the inference pipeline, not to end-to-end response generation. TurboQuant was tested only on models around 8 billion parameters. Effects on the 70-billion and 400-billion parameter models that power commercial AI products remain unverified. And as of today, there is no official code release. As one developer put it: "You can't pip install it."
TurboQuant also only affects inference, the process of running a trained model. It does nothing for training, which remains the largest driver of memory chip procurement at hyperscalers. Andrew Jackson at Ortus Advisors suggested the technology may make "little difference to demand given the extreme supply constraints." Lee Jong-wook at Samsung Securities framed it more bluntly: "As long as AI companies are competing on performance rather than cost, cost optimization will not affect semiconductor demand. The time to worry is when AI companies stop competing."
The Bigger Story
The most revealing detail in the TurboQuant saga is not the algorithm itself but what happened around it. Google published a compression breakthrough and simultaneously increased its AI spending by 100%. SK Hynix has its entire memory chip capacity sold out through the end of 2026. Micron has exited the consumer memory market entirely to focus on enterprise AI customers. Samsung's new fabrication plants will not reach full-scale operations until the end of 2027. SK Group chairman Chey Tae-won has said the shortage will last until 2030.
This is the pattern the market keeps learning and then forgetting. DeepSeek made AI training more efficient, and within two quarters, hyperscaler capex hit record highs. If TurboQuant makes AI inference more efficient, the most likely outcome is not that companies buy fewer memory chips but that they run more AI workloads on the same hardware, which creates demand for even more hardware to handle the expanded use cases.
Chae Min-suk at Korea Investment and Securities identified the core misunderstanding. The sell-off, he argued, "stemmed from an interpretation error caused by confusing the roles of memory capacity and memory bandwidth." Compressing the KV cache does not reduce the total memory a server needs. It reduces the data size per operation, which allows more operations on the same hardware, which generates demand for more throughput, which requires more chips.
Ben Barringer at Quilter Cheviot called TurboQuant "evolutionary rather than revolutionary." That may be the most accurate assessment. The algorithm is real, the efficiency gains are meaningful, and the long-term effect on AI infrastructure economics is worth watching. But the idea that a blog post about KV cache compression will meaningfully slow the largest infrastructure buildout in the history of computing requires a theory of change that no analyst has yet articulated. The memory chip companies are not selling less. They literally cannot make chips fast enough. TurboQuant does not change that equation. It just makes each chip more useful, which, if Jevons was right, means the world will want even more of them.
Sources
- Google Research Blog: TurboQuant: Redefining AI Efficiency With Extreme Compression - Original announcement by Amir Zandieh and Vahab Mirrokni
- Seoul Economic Daily: Google's TurboQuant Paper Rattles Samsung, SK Hynix Memory - Morgan Stanley's Shawn Kim Jevons Paradox analysis and Asian market impact
- TechCrunch: Google Unveils TurboQuant, a Real-Life "Pied Piper" for AI Memory - Technical overview and community reaction
- TrendForce: Decoding Google's TurboQuant: 6x KV Cache Cut - Industry analysis of real-world compression ratios and limitations
- Benzinga: Micron Stock's Rally Looked Unstoppable Until Google's TurboQuant Hit - Micron-specific stock impact, BofA and Wells Fargo analyst commentary